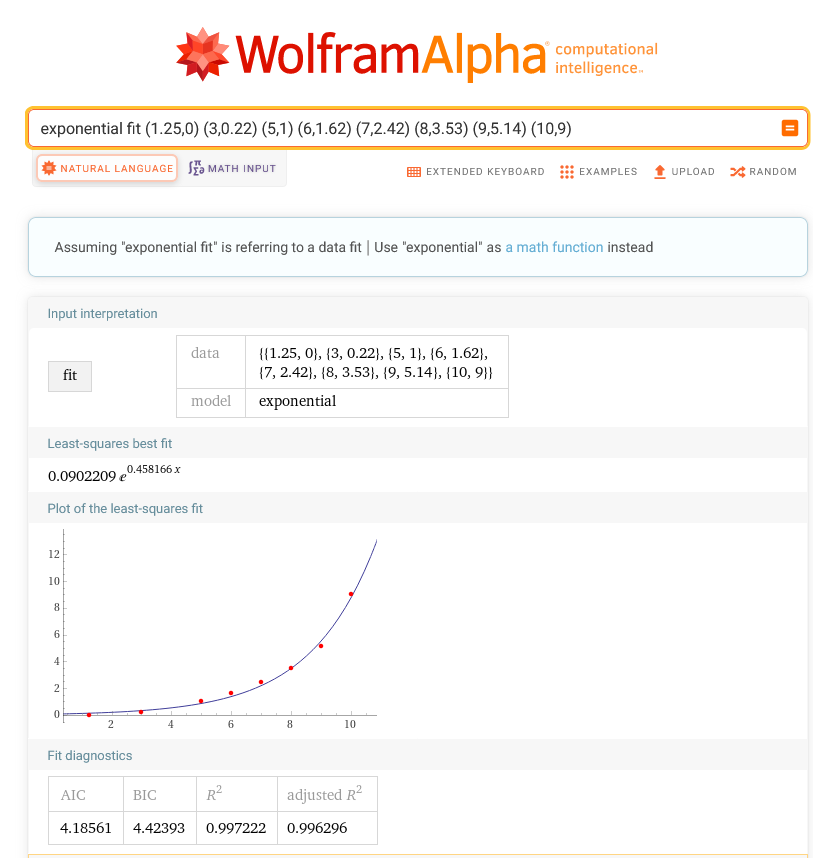
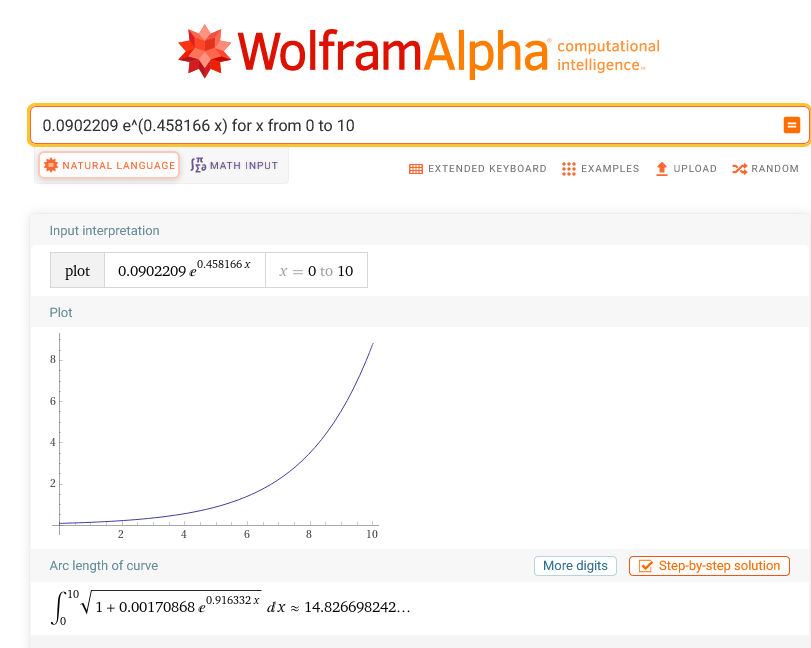
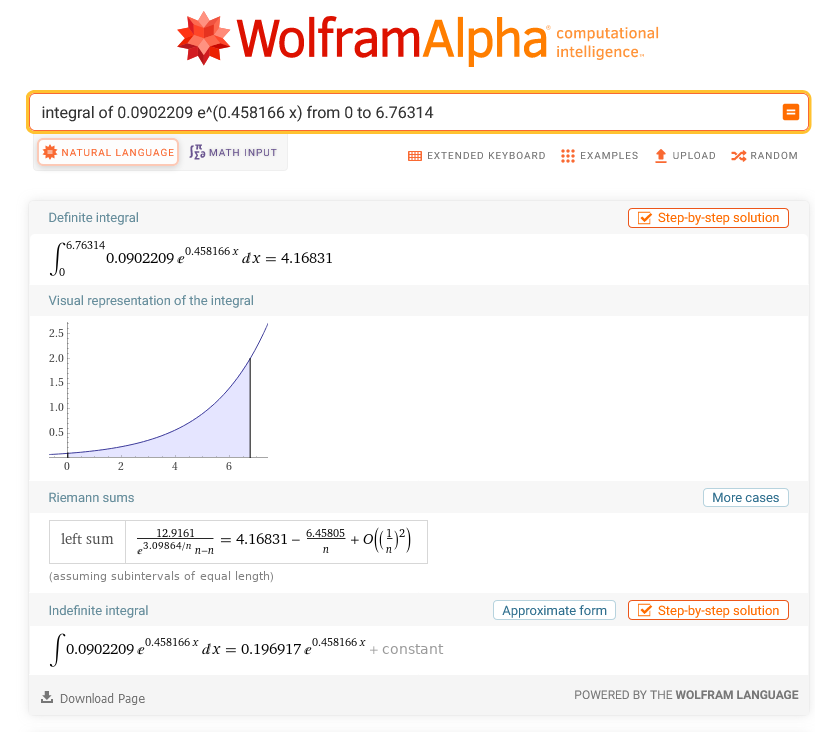
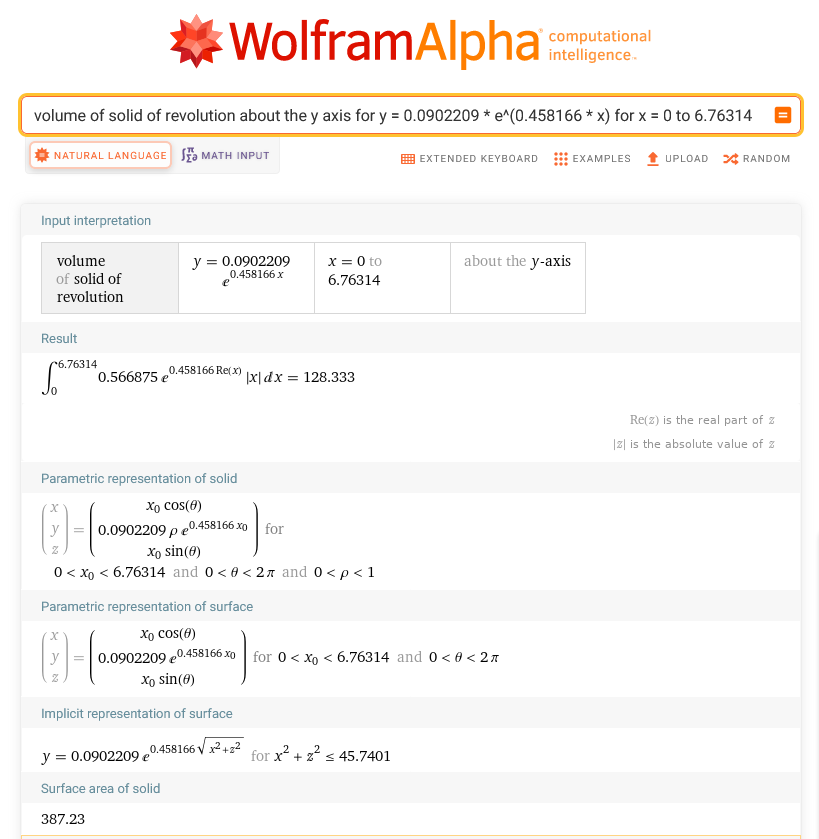
In the movies, heroes manipulate complex graphics environments using only their keyboard; no mouse in sight. Descending from the movies realm to reality, the command line, not the GUI, is where heroes save the day.
This article intends to be helpful for those who are already command line (CLI) users. Complete beginners are of course encouraged to read on, even though they may not grasp all the advantages immediately and perhaps there is a lot of other more important things to learn when starting. On the other hand, I expect long time CLI users to already work similarly. I do hope they might also find interesting tricks to adopt.
The motivation
First of all, why be more effective? Not everyone wants to, and that is fine. These tips contribute to two primary objectives:
Looking back on everything I tried over the years, I'd like to illustrate those tips that I believe brought me the most "bang for the buck", the most value with the smallest effort and the ones that are more easily applicable to anyone else.
Assumptions
I'm going to assume you are using bash on Linux or MacOSX. A recent MacOSX install shouldn't be too different. Windows has bash too these days, so hopefully these suggestions will be widely applicable.
I'm also going to assume that you, reader, already know how to comfortably move around the CLI (CTRL + A, CTRL + E, CTRL + W, …), recall past commands (!<nnn>, !!, CTRL + R) or arguments (ALT + .). There is enough material to write other posts about this. Let me know and I'll be happy to write it!
1. Shell History
Here we go, first recommendation: use your shell history capabilities.
If you are not already doing that, you can search through your shell history — all the commands you have typed — with CTRL + R. However, the default configuration for bash only keeps up to a certain number of commands.
Computers and hard drives being what they are in 2020, there's no reason why you shouldn't extend your shell history to record all commands you have ever typed from the very beginning of your system history. When I setup a new computer, I normally copy over all my $HOME files, so my command history extends, time-wise, well beyond the system I am writing this on.
My shell command history starts in October 2015, when I first learned this trick. Here's how to do it:
# /etc/profile.d/extended_history.sh
# Show the timestamp for each entry of the history file
export HISTTIMEFORMAT="%Y-%m-%dT%H:%M:%S "
# Ensure the history file size and entry number is large
# enough to record years upon years of history
export HISTFILESIZE=500000000
export HISTSIZE=50000000
At least on Debian and derivative systems, dropping a file into /etc/profile.d/ makes it part of the system-wide profile settings, so that is a handy way of applying those settings to all users.
As a result, the history command will work as before, but the numeric index of each command will not reset every time you open a new shell, or every time the history file gets over a certain size, either in number of entries or in file size.
Here's how the history command output looks like with those settings:
23 2015-10-06T19:51:30 git diff
24 2015-10-06T19:51:33 git add locale/en/LC_MESSAGES/django.pot
25 2015-10-06T19:51:49 git status -uno
26 2015-10-06T19:51:51 git commit -a
27 2015-10-06T19:52:11 git push
28 2015-10-06T20:11:35 make test-recommender_translations
29 2015-10-07T18:53:33 vim ~/notes/recsys/impressions-tracking.txt
At the moment, my shell history file (~/.bash_history) is almost 7 Mb, corresponding to a little less than five years worth of commands. There is really no risk of running out of disk space, so keep those commands around.
Keeping a full history has obvious advantages:
- If you don't remember how you did something or specific options to a command, you can always use
history | grep xyz (or CTRL + R) to find out, and all the commands from months (or years!) back will be there. Obviously this does not apply retroactively :-)
- If you remember only when you did something but not what it was, it's also easy to grep for specific dates and times.
- You can easily analyze your shell usage patterns, for example finding what are the top 50 shell commands you have ever used:
$ history \
| awk '{ print substr($0, length($1 $2) + 3) }' \
| sort | uniq -c \
| sort -rn \
| head -50
# on one line:
$ history | awk '{ print substr($0, length($1 $2) + 3) }' | sort | uniq -c | sort -rn | head -50
In order, those lines do the following:
history: take all history entriesawk ...: remove the entry numeric index and timestamp, to only display the command itself and all the argumentssort | uniq -c: count the number of occurrences for all the distinct entriessort -rn: reverse sort numerically all the commandshead -50: take the first 50 commands
If you are confused by all these commands, don't worry too much about them. It's just a way to count the most typed commands in your history.
As a curiousity, here's some of my top commands:
13071 ls -l
7422 git diff
6338 git status
3469 cd ..
2219 git push
1816 git pull
1499 git commit -a
1367 git log
940 git commit
851 gpr
687 gcs
400 srdm platf
348 vimp
333 l1
314 srdm merl
306 dcu
302 mp;rl-f
206 gce
196 realias
169 gcm
153 mptr;rl-f
152 gc-
2. Fast Directory Changes
One of the most frequent operations on the command line is moving among directories, with the cd built-in command.
Especially if you've worked for a long time on many projects, or if you work with Java, you tend to have a lot of directory levels nested quite deeply. The cd commands is then tedious to type. Using tab to invoke your shell autocomplete comes in handy, but not having to type at all can easily beat that.
This is a trick I learned from Damian Conway's Productive Programmer course. He was in Oslo a few years ago, and with the help of my company we organized to have him hold this course internally.
The idea is to use a bespoke shell (or Perl, Python, Node, …) script, to quickly navigate to any directory. Example. Currently I am working on a project called merlin, whose parent directory is ~/src/work. Every time I want to do something in this project, I have to:
cd ~/src/work/merlin
Within that project, there are a bunch of directories, so you could end up writing something like:
cd ~/src/work/merlin/gameserver/prototype/java/src/
The idea is to construct a program that can do the "typing" for you, so you'd use the following command instead:
cd2 src w merl g p j s
I called it cd2 but you can call it however you like of course. This program should:
- take as input a list of string arguments
- try to expand them to the closest directory name entry
- if a directory is found, navigate to it
- take the next argument and repeat this cycle
When this is done, your shell will be left into the target directory of your choice without any long typing or waiting for autocomplete misfired tabs.
I chose to implement my script in bash for simplicity and call it ~/bin/search-directory.sh. The code is almost trivial and here it is in its entirety:
#!/bin/bash
#
# Search through the home directory space based on the
# list of string arguments given as input.
# From an idea by Damian Conway.
#
# Start from my home directory
SRC_DIR=~
# Take all arguments given as input
ARGS="$*"
# For each argument, try to expand it into the nearest directory name
# at the current level
for dir in $ARGS ; do
sub=$(find -L "$SRC_DIR/" -mindepth 1 -maxdepth 1 -type d -name "$dir*" \
| sort \
| egrep -v '\.egg-info' \
| head -1)
if [ ! -z "$sub" ]; then
# We found a subdir, search will proceed from there
SRC_DIR=$sub
else
# Stop: we didn't find any matching entry.
exit 1
fi
done
echo "$SRC_DIR"
exit 0
One could clearly do better than this by employing more sophisticated logic. Initially I thought I'd need better, but this simple script has served me well for the past years, and I don't want to complicate it unnecessarily.
There is one more obstacle to clear though. The script will print the final directory match and exit, without affecting the parent shell's current directory.
How to make the active shell actually change directory? I added a tiny function to my ~/.bashrc file:
# `srd` stands for 'source directory'
srd () {
match=$(~/bin/search-directory.sh src $*)
if [ ! -z "$match" ]; then
echo "→ $match"
cd "$match"
fi
}
I made the function always supply the src directory by default, so I don't have to type that either. With these bits set up, you can then move to the example directory above with the command:
srd w merl g p j s
And this is just the beginning :-)
Read on for how to combine this technique with the power of aliases and shorten the command even more.
3. Aliases
Shell aliases are a simple way to define or redefine commands.
The typical example would be to shorten common options for your commands. If you know you always type ls -la, you might want to teach that to your shell. The way to do that is:
$ alias ls='ls -la'
From then on, every time you type ls, your shell will automatically expand the command to ls -la.
Based on what I have seen during my career, shell aliases are something that relatively few people are using. Right now, my shell configuration contains almost 500 lines of aliases, of which around 200 I keep active and probably 30-50 I normally use.
I wasn't always such a heavy alias user. I became one when I had the fantastic experience to work with the Fastmail team in Australia for a period of a few months. I learned how they were doing infrastructural and development work and from the first day I saw they were using a ton of shell commands that were completely obscure to me.
I was quite good at operations/sysadmin work, but after seeing how that team worked, the bar was forever raised and it sank in that I had still a lot to learn. I still do :-)
I use aliases for many things, but mainly to not have to remember a lot of unnecessary details. Here's a few from my list:
| Alias |
Expanded command |
What/why |
less |
less -RS |
shortening and options expansion. -RS is to show ANSI color escapes correctly and avoid line wrapping |
gd |
git diff |
shortening |
gc- |
git checkout - |
switch to the previous git branch you were on |
vmi |
vim |
saver for when I type too quickly |
cdb |
cd .. |
cd "back" |
cdb5 |
cd ../../../../../ |
to quickly back out of nested directories |
kill-with-fire |
killall -9 |
for those docker processes… |
f. |
find . -type f -name |
find file names under the current directory tree |
x1 |
xargs -I{} -L1 |
simplify using xargs, invoking commands for each line of input f.ex. |
awk<n> |
awk '{ print $<n> }' |
for when you need to extract field number from a text file or similar. Ex.: awk5 < file extracts the 5th field from the file |
vde1 |
ssh varnish-de-1.domain.com |
host-based alias. I don't want to have to remember hostnames, so I add aliases instead, with simple mnemonic rules, such as vde1 -> varnish node 1 in the german cluster |
jq. |
jq -C . |
when you want to inspect JSON payloads, f.ex. curl https://some.api | jq. |
dcd |
docker-compose down |
is anybody really typing docker-compose ? |
dcp |
docker-compose pull |
|
dcu |
docker-compose up |
|
dkwf |
docker-kill-with-fire |
shorthand for docker stop + docker rm or whatever sequence of commands you need to stop a container. See? I don't have to remember :-) |
db |
docker-bash |
db postgres instead of docker exec -it container-id bash |
dl |
docker-logs |
same for docker logs -f ... |
Some aliases that I have added thinking they'd be useful I have rarely used. Some have become a staple of my daily CLI life. Sometimes, if a new alias catches on only depends on the first few days. If you make a mindful effort to use it, there's a good chance it will stick (if it's actually good).
To make aliases persistent, instead of typing the alias command in your shell, you can add it to your ~/.bashrc file as you can with any other command. You can also create a ~/.aliases file and keep all your aliases there. If you do that, you then need to include your aliases file in your bash configuration. You do that by adding (only once) this line to your ~/.bashrc:
# ~/.bashrc
...
source ~/.aliases
Every time you feel the need to add a new alias, you can simply edit the ~/.aliases file and reload it into your active shell (source ~/.aliases). When you get tired of that, you can use another trick from Conway's course, and add the last alias you will ever need:
alias realias="${EDITOR:-vim} ~/.aliases; source ~/.aliases"
Typing realias will bring up the alias file in your editor and when you save it and exit, all the new aliases will be immediately available in the parent shell.
Once you start down this path, your creativity won't stop seeing new ways to work smarter and faster.
4. Directory Autorun
This is one of the most recent additions to my arsenal. I found myself typing the same commands over and over whenever I entered specific directories.
The idea is then simply to have a sequence of commands automatically executed for me whenever I enter a directory. This is extremely useful in many occasions. For example, if you want to select a specific Python virtualenv, a Node.js version or AWS profile whenever you enter a specific directory.
I chose to do this by dropping an .autorun file in the target directory. Here's a tiny .autorun I have in a Javascript-based project:
#!/bin/bash
REQUIRED="v11.4.0"
CURRENT=$(nvm current)
if [ "$CURRENT" != "$REQUIRED" ]; then
nvm use $REQUIRED
fi
In this case I want the shell to automatically activate the correct node.js version I need for this project whenever I enter the directory. If the current version, obtained through nvm current, is already the one I need, nothing is done.
It's quite handy, and I immediately got used to it. I can't do without it now. Another example, to select the correct AWS credentials profile and Python virtualenv:
#!/bin/bash
if [ -z "$AWS_PROFILE" -o "$AWS_PROFILE" != "production" ] ; then
export AWS_PROFILE=production
echo "— AWS_PROFILE set to $AWS_PROFILE"
fi
if [ -z "$VIRTUAL_ENV" ] ; then
source .venv/bin/activate
echo "— Activated local virtualenv"
fi
The glue to make this work is a couple of lines added to your ~/.bashrc file:
# Support for `.autorun` commands when entering a directory
PROMPT_COMMAND+=$'\n'"[ -s .autorun ] && source ./.autorun"
If you are concerned other users could use your machine, or even in general if you like to keep things tidy, ensure you set appropriate permissions for these .autorun files. A chmod 0600 .autorun could be in order.
Remember to run source ~/.bashrc if you make changes to that file, or they won't immediately reflect on your active shell session.
5. SSH Configuration
SSH is one of the most powerful tools in your arsenal. It can be used to tunnel, encrypt and compress data for connections to arbitrary protocols. I'm not going to cover that functionality here. There are good tutorials out there already, such as this and this.
A smart ssh configuration can help you be more effective on the command line. I'd like to show three specific examples that I use every day:
- Persistent ssh connections
- Hostname aliases
- Automatic ssh key selection
Persistent ssh connections
If you connect to remote hosts often, I'm sure you have noticed the amount of time it takes to establish a new ssh connection. The higher the latency, the longer it takes. It is normal for that initial handshake — where a lot of things happen — to take 2 to 5 seconds.
Performing many small operations via ssh can waste a notable amount of time. One solution to this problem is the transparent use of persistent ssh connections.
The connection is established the first time you ssh (or scp) to a host, and next time you perform a similar operation towards the same host and port, the same TCP/IP connection will be used. This implies that the connection remains active after the ssh command has completed.
The ssh configuration directives that enable this behaviour are the following:
# Normally this is in ~/.ssh/config
ControlMaster auto
ControlPath /var/tmp/ssh_mux_%h_%p_%r
ControlPersist 1h
ControlMaster auto enables this behaviour automatically, without you having to specify whether you want to use shared connections (the ones already opened from before) or not. In particular cases, you may want to specify ControlMaster no on the command line to prevent ssh from using an already open connection. Generally this is not desired though, so ControlMaster auto will normally do what you want.
ControlPath is the filename template that will be used to create the socket files, where:
%h is the hostname%p is the port number%r is the username used to connect
ControlPersist is the option that determines how long the connections will stay shared waiting for new clients after being established. In my case, I set it to 1h (one hour) and that works well for me.
In case you want to know more about ssh configuration, I recommend reading the related man page. On linux, that is available with:
man 5 ssh_config
Hostname aliases and key selection
I mentioned I want to get unnecessary details out of my memory as much as possible. The ssh configuration file has lots of useful directives. One of these is the per-host configuration blocks.
If you need to connect to a host quite often and its name is not particularly memorable, like an AWS or GCP hostname, you can add host-specific directives to your ~/.ssh/config file:
# ~/.ssh/config
...
Host aws-test
Hostname 1.2.3.4
User my-username
From then on, you can use the command ssh aws-test to connect to this host. You won't have to remember the IP address, or the username you need to use to connect to this host. This is particularly useful if you have dozens of hosts or even projects that use different usernames or host naming schemes.
When you have to work with different projects, it's good practice to employ distinct ssh key-pairs instead of a single one. When you start using ssh, you have a ~/.ssh/id_rsa (or ~/.ssh/id_dsa) file, depending on the type of key and an associated ~/.ssh/id_rsa.pub (or ~/.ssh/id_dsa.pub).
I like to have several key-pairs and use them in different circumstances. For example, the key that is used to connect to a production environment is never the same used to connect to a staging or test environment. Same goes for completely different projects, or customers if you do any freelance work.
Continuing from the example above, you can tell ssh to use a specific private key when connecting to a host:
Host aws-test
Hostname 1.2.3.4
User my-username
IdentityFile ~/.ssh/test_rsa
Host aws-prod
Hostname 42.42.42.42
User my-username
IdentityFile ~/.ssh/prod_rsa
Host patterns work too:
Host *.amazonaws.*
User my-aws-username
IdentityFile ~/.ssh/aws_rsa
Host *.secretproject.com
User root
IdentityFile ~/.ssh/secret_rsa
Final tip
The more I write, the more it feels there is to write about the command line :-) I'll stop here for now, but please let me know if you'd like me to cover some more basic — or maybe more advanced? — use cases. There are a lot of useful tools that can make you more effective when using the command line.
My suggestion is to periodically gather information about how you use the command line, and spend some time to reassess what are the most frequent commands you use, if there are new ways to perform the same actions, perhaps entirely removing the need to type lots of commands.
When I have to do boring, repetitive tasks, I can't help but look into ways to get myself out of those. Sometimes writing a program is the best way to automate those tasks away. It may take more in the beginning, but at least I managed to transform a potentially boring task into programming, of which luckily I'm never bored :-)

 Other funny memes that were shared:
Other funny memes that were shared: