According to meta::cpan records, the first release of pgtop is dated April 26, 2005, which makes this little software more than 15 years old!
Back then I had just found out about the brilliant mytop by Jeremy Zawodny, and my day-to-day experience being on Postgres, IIRC version 6.5.3, I decided to try and “convert” mytop to Postgres.
Being quite naive, I thought the endeavour would be much easier than it really was. I’m glad I started though, which is why pgtop exists in the first place. It’s not the only one either. I seem to remember a few similar pgtop projects by other programmers.
After using MySQL and Percona Server for many years, due to a new job, I have gone back to Postgres, version 9.5 and 10 at this time. In recent months, I have done some work to improve performance of our database queries, and remembered writing and using pgtop years before.
Since I lost(*) the original sources, I tried the pgtop version I last uploaded to CPAN, 0.05, dated 2008. It did work, in the sense that I could run the same perl code unmodified, a great testament to Perl as language and as runtime. It didn’t work because the underlying Postgres meta tables that were used in version 6 changed their schema in the 10-12 years since :-)
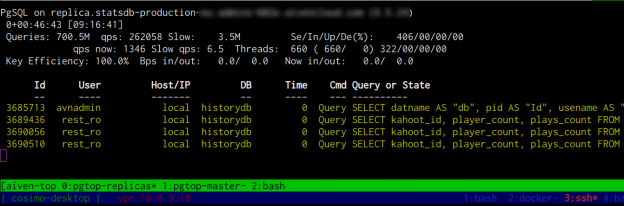
I spent some time to adapt the metadata queries to work with recent Postgres versions, and was slightly amused by the quality of my 15 year old code… The best feeling about this little tool was to rediscover how useful a few dozen lines of code can be. The service provider monitoring helps, but doesn’t even come close to the level of detail pgtop can provide.
After getting pgtop to work again, I quickly added a few more useful features. I was pleased by the efficiency with which I could work on this tool, considering its age.
So far I added just what was strictly necessary to me:
- Updated pgtop to the current decade. Now requires perl >= 5.014
- Fixed to work with Postgres >= 9.0
- Added a sample Dockerfile to build and run pgtop as Docker container
- Added a
--configoption, to load arbitrary config files. This is useful if you want to monitor several databases at once, for example in a tmux session. The config file supports all the options that are available on the command line. - Implemented a query killer command, activated pressing K to kill at once all queries slower than a given threshold, in seconds. This is useful if the database is overwhelmed by a lot of slow queries. I don’t recommend using it, particularly if it involves killing UPDATE or INSERT queries, but it can be quite useful.
- Added a
--slow_threshold option, to consider queries slow if they have been running for longer than the given value (in seconds). Now the tool highlights slow queries in bold yellow, and logs all the slow queries to apgtop.logfile. - Added a
--slack_webhookoption, to automatically notify a slack channel if a query crosses the slow threshold runtime value. All the information about the slow query including the SQL will be included in the slack message.
Please let me know if you give it a try! :-)